
autocontext: The Recursive Self-Improving Loop That Teaches AI Agents to Get Better Over Time
The bottleneck for AI agents isn’t intelligence. It’s memory. autocontext is the feedback loop that fixes it.
Your agent works. Then the context window fills up, the provider compacts the conversation, and it forgets the thing it figured out twenty minutes ago. You restart. It makes the same mistake. You patch the prompt. It works for a week. Then a different failure mode shows up and you’re back to reading logs at 2am.
This is the actual day-to-day of building with AI agents. Not the demo. The production reality where agents start cold every time, carry no institutional knowledge, and treat every invocation like it’s their first day on the job.
Jay Scambler, Managing Partner at Grey Haven AI, built autocontext to fix this. And he’s not alone — a wave of recursive self-improvement tools is converging around the same insight: the model isn’t the bottleneck. The infrastructure is.
What autocontext Actually Does
autocontext runs your agent against a task repeatedly. After each run, a multi-agent team analyzes the results and updates a shared knowledge base. The next run inherits everything the previous run learned.
The system ships as both a Python package (pip install autoctx) and a TypeScript package (npm install autoctx), with a CLI, real-time dashboard, and an MCP server exposing 50+ tools for integration with Claude Code, Cursor, OpenClaw, and other MCP-compatible environments.
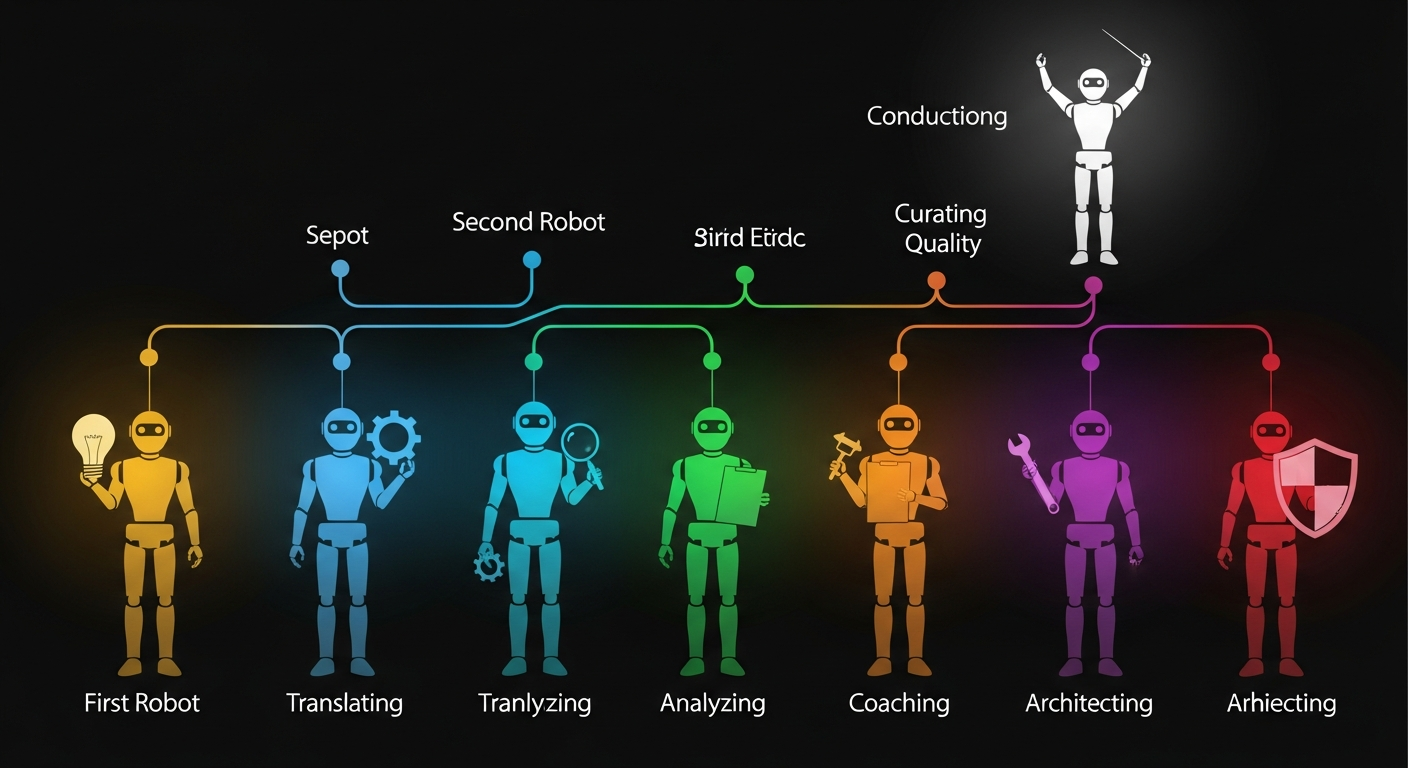
At its core is a 7-role agent pipeline:
- Competitor generates strategy candidates for the task
- Translator converts raw output into validated, structured JSON
- Analyst examines what happened — findings, root causes, recommendations
- Coach distills the analysis into playbook updates and competitive hints
- Architect proposes tooling improvements and can modify the agent pipeline itself
- Curator gates the quality of knowledge updates — rejecting proposals that would hollow out the playbook, deduplicating redundancies, and resolving contradictions
- Orchestrator sequences the entire pipeline, handling parallel execution, retry logic, and handoffs
The Orchestrator doesn’t generate content. It’s the conductor: nothing runs without it.
The Playbook: Where the Magic Happens
The playbook is the key abstraction. It’s a living document that grows across runs, containing:
- Strategies that worked, with the scores that proved they worked
- Strategies that failed, with specific failure modes to avoid
- Tier-specific rules (e.g., “when resources are low, keep total commitment under 1.05”)
- Generated tools that automate analysis patterns the Architect discovered
Knowledge only persists when it’s validated. Each generation runs through tournament matches (for game scenarios) or LLM judge evaluation (for agent tasks) with Elo-based progression gating. Strategies that don’t improve get rolled back. The Curator agent provides defense-in-depth: it rejects any playbook update that shrinks content below 30% of the original (preventing “hollowing”), strips required structural markers, or introduces contradictions.
When Scambler ran autocontext against a grid capture-the-flag scenario, it accumulated 33 distinct lessons across 2 generations. Strategies evolved from generic parameter sweeps to tier-classified approaches with specific resource density thresholds. The playbook went from empty to 5,870 characters of actionable knowledge.
An agent starting fresh with a populated playbook outperforms one starting cold. That’s the compounding effect.
Two Kinds of Scenarios
autocontext ships with 11 scenario families, but the core distinction is between two types:
Game scenarios are adversarial environments with clear win conditions — capture-the-flag, Othello, resource allocation. They give you something most agent benchmarks don’t: an objective scoring function that doesn’t depend on an LLM judge’s opinion. When your agent’s Elo goes up, it actually got better.
Agent tasks are open-ended problems that look more like real work: write an incident postmortem, design a clinical trial protocol, construct a formal proof, draft a cybersecurity incident response plan. These use LLM judges with multi-dimensional rubrics. Describe what you want in natural language and autocontext generates a spec, builds a rubric, and starts the improvement loop.
The two are complementary. Games give hard guarantees. Agent tasks give domain flexibility. And the system extends to 9 more families: simulation (with fault injection), artifact editing (with diff tracking), investigation (evidence chains), workflow (compensation and rollback), negotiation (opponent modeling), schema evolution, tool fragility, operator loops, and multi-agent coordination.
The Evaluation System That Makes It Work
Evaluation quality determines whether the loop improves or just churns. autocontext uses a multi-layered system:
Elo ratings track agent performance across tournament matches, starting at 1500 with a K-factor of 24. A HypothesisTree maintains multiple competing strategies simultaneously using Thompson sampling — balancing exploration of new approaches against exploitation of proven ones. When too many hypotheses accumulate, the lowest-Elo nodes get pruned.
Multi-dimensional rubrics for agent tasks score outputs across configurable dimensions (accuracy, clarity, actionability, etc.) independently, so revisions can target the weakest dimension instead of blindly rewriting everything.
Gating decisions determine whether improvements persist. The rapid gate is binary: any positive delta advances, zero or negative rolls back. The trend-aware gate incorporates historical patterns. The backpressure gate uses configurable minimum delta thresholds.
Parse resilience matters because LLM outputs are messy. The judge has a 4-tier fallback parser: marker-delimited JSON, raw JSON extraction, regex patterns, and structured retry. In adversarial testing, malformed outputs get thrown at the loop and it recovers every time.

Frontier to Local: Start Expensive, End Cheap
One of the more ambitious pieces: autocontext can distill strategies from frontier models into local models via MLX on Apple Silicon.
The workflow:
- Run discovery with Claude Opus 4.6 or GPT-5.4 (or whatever frontier model you prefer)
- Export training data from the run database
- Train a small local model via MLX (
autoctx train --backend mlx) - Route future runs through the local model when it’s strong enough
- Fall back to the frontier model when the local model is weak
This isn’t theoretical. The full pipeline is implemented: export, training loop with git-based experiment state machine, MLX model with GQA attention and RoPE, safetensors checkpoints, and an MLXProvider that plugs into the same generation loop. Training requires Apple Silicon (MLX uses Metal directly). A CUDA backend is also available for GPU servers.
The practical implication: a developer with an M-series Mac can explore with expensive frontier models, then distill successful patterns into a local model that runs at zero cloud cost.
The Wave: autocontext in Context
autocontext didn’t emerge in isolation. It’s part of a March 2026 convergence of recursive self-improvement tools, each attacking the same fundamental problem from different angles.
Karpathy’s autoresearch (41,500 stars)
Released March 6, 2026, Andrej Karpathy’s autoresearch lets AI agents conduct autonomous ML research overnight. 630 lines of Python. The agent modifies train.py, trains for 5 minutes, evaluates, keeps or discards, repeats. In two days: 700 experiments, ~20 additive improvements, 11% efficiency gain on “Time to GPT-2.”
Shopify’s CEO tried it on internal data: 37 experiments overnight, 19% performance gain. The announcement hit 8.6 million views on X and coined the “Karpathy Loop.” autocontext’s training pipeline and iterative experiment design are directly inspired by this work.
The Ralph Wiggum Technique (Geoffrey Huntley)
Before Karpathy formalized the loop, Geoffrey Huntley (ex-Optiver, ex-Canva) popularized the Ralph Wiggum technique — a bash loop feeding AI output back into itself until convergence, with each iteration updating AGENTS.md files so future iterations inherit discovered patterns. His insight: “everything is a Ralph loop.” Software development has transformed from building brick-by-brick into programming loops that auto-heal and compound knowledge.
Huntley’s observation that Claude 3.7 performance degrades at 147K-152K tokens (despite advertising 200K) led to the subagent spawning pattern that’s now standard practice.
GEPA (ICLR 2026 Oral)
GEPA is a reflective prompt evolution framework that outperforms GRPO by 6% average using 35x fewer rollouts. Its key innovation: instead of collapsing execution traces into a single score, evaluators return Actionable Side Information — error messages, logs, reasoning traces — that an LLM reads to diagnose failures and propose targeted mutations. It maintains a Pareto front of complementary candidates rather than converging on a single “best.”
Adopted by Shopify, Databricks, and OpenAI. GEPA directly influenced autocontext’s approach to multi-dimensional evaluation and knowledge-preserving optimization.
Recursive Language Models / RLM (Prime Intellect)
RLMs propose that long inputs shouldn’t be fed directly into neural networks — they should be treated as environment variables in a Python REPL that the LLM interacts with symbolically. This handles inputs up to 100x beyond model context windows. Prime Intellect calls it “the paradigm of 2026.” autocontext’s REPL-Loop Mode is directly inspired by this architecture.
Helios (snoglobe)
Helios is an autonomous research agent with SSH-based remote execution, persistent memory checkpointing, automatic metric parsing, and composable sleep triggers. It represents the “agent cockpit” pattern and shaped autocontext’s operator experience for long-running autonomous sessions.
The Harness Engineering Thesis
All of these projects point to the same conclusion, which OpenAI articulated in February 2026 when they coined the term harness engineering: the competitive advantage in AI is no longer the model. Models are increasingly commoditized. The advantage is now:
- The harness — infrastructure, constraints, feedback loops, lifecycle management
- The trajectory data captured by the harness (used for fine-tuning and distillation)
- The context engineering system — what information reaches the model, when
OpenAI demonstrated this internally: Codex agents produced approximately one million lines of production code over five months. Engineers stopped writing code and started “designing environments, specifying intent, and providing structured feedback.”
The computing analogy that stuck: Model = CPU. Context Window = RAM. Agent Harness = Operating System. Agent = Application.
autocontext is one of the most complete open-source implementations of this pattern. It combines the recursive improvement loop (Karpathy), the knowledge persistence layer (Ralph/Huntley), the multi-dimensional evaluation system (GEPA), the REPL-based context management (RLM), and the operator cockpit (Helios) into a single integrated system.
Beyond Code: Where This Gets Interesting
The scenario system is deliberately domain-agnostic. autocontext’s internal escalation tests go well beyond software engineering:
- Formal proofs: constructing and verifying step-by-step mathematical arguments
- Clinical trial design: protocol generation with randomization, demographics, and regulatory constraints
- Geopolitical wargaming: crisis response planning with competing stakeholder objectives
- Financial portfolio optimization: regime-aware allocation strategies
- Cybersecurity incident response: triage, containment, and remediation planning
- Drug interaction analysis: evaluating compound pairs for safety and efficacy
- Ecosystem simulation: multi-cycle environments where agents adapt across changing conditions
The pattern is the same: run, evaluate, learn, persist, repeat. The harness doesn’t care whether the agent is writing code or designing a clinical protocol. It cares whether the output got better.
OpenClaw Integration
For builders in the OpenClaw and Claude Code ecosystem, autocontext ships with direct integration:
- MCP server (
autoctx mcp-serve): Exposes 50+ tools for agent integration — scenario management, tournament execution, knowledge reading, task queuing, artifact management, and skill discovery - OpenClaw skill packaging: Distilled models and learned behaviors can be packaged as OpenClaw-compatible skills via
openclaw/skill.py - CLI-first contract:
autoctx run --scenario grid_ctf --gens 3kicks off a scenario; JSON output contracts enable programmatic consumption
The MCP server means any MCP-compatible environment (Claude Code, Cursor, OpenClaw) can drive autocontext’s evaluation and improvement loops programmatically.
Five Takeaways
1. The loop has closed. AI systems can now meaningfully improve AI systems. What was a theoretical concern in AI safety has become an observable, measurable engineering practice. autocontext, autoresearch, and GEPA all demonstrate this in production.
2. Knowledge persistence is the real bottleneck. The model is smart enough. The problem is that every invocation starts cold. autocontext’s playbook system, Huntley’s AGENTS.md pattern, and Letta’s three-tier memory architecture all attack the same gap: agents need institutional memory.
3. Evaluation quality determines everything. A loop that evaluates poorly just churns. autocontext’s multi-dimensional rubrics, Elo-based gating, and Curator quality gates ensure that only validated improvements persist. GEPA’s Actionable Side Information takes this further by giving the optimizer diagnostic-quality feedback, not just scores.
4. Frontier-to-local distillation is practical now. MLX on Apple Silicon means a developer with an M-series Mac can explore with Claude Opus or GPT-5.4, then distill successful patterns into a local model at zero cloud cost. This isn’t experimental — autocontext ships the full pipeline.
5. Harness engineering is the new competitive moat. Models are commoditizing. The harness — infrastructure, constraints, feedback loops, and the trajectory data it captures — is where lasting advantage lives. “2025 was agents. 2026 is agent harnesses.”
Get Started
git clone https://github.com/greyhaven-ai/autocontext.git
cd autocontext/autocontext
uv venv && source .venv/bin/activate && uv sync --group dev
# Run a deterministic test (no API keys needed)
AUTOCONTEXT_AGENT_PROVIDER=deterministic uv run autoctx run \
--scenario grid_ctf --gens 3 --run-id quickstart
# Run with Anthropic
AUTOCONTEXT_AGENT_PROVIDER=anthropic \
AUTOCONTEXT_ANTHROPIC_API_KEY=your-key \
uv run autoctx run --scenario grid_ctf --gens 3
The repo: github.com/greyhaven-ai/autocontext
Follow Jay Scambler on X (@JayScambler) for updates and applied use cases.
This article analyzed research across the autocontext codebase, Karpathy’s autoresearch, GEPA, the Ralph Wiggum technique, Recursive Language Models, Helios, and the broader harness engineering movement to present a comprehensive view of the recursive self-improvement wave reshaping AI agent development in 2026.