
Gemini Embedding 2: one model to embed them all
Google’s first multimodal embedding model puts five content types in the same vector space. And it costs nothing.
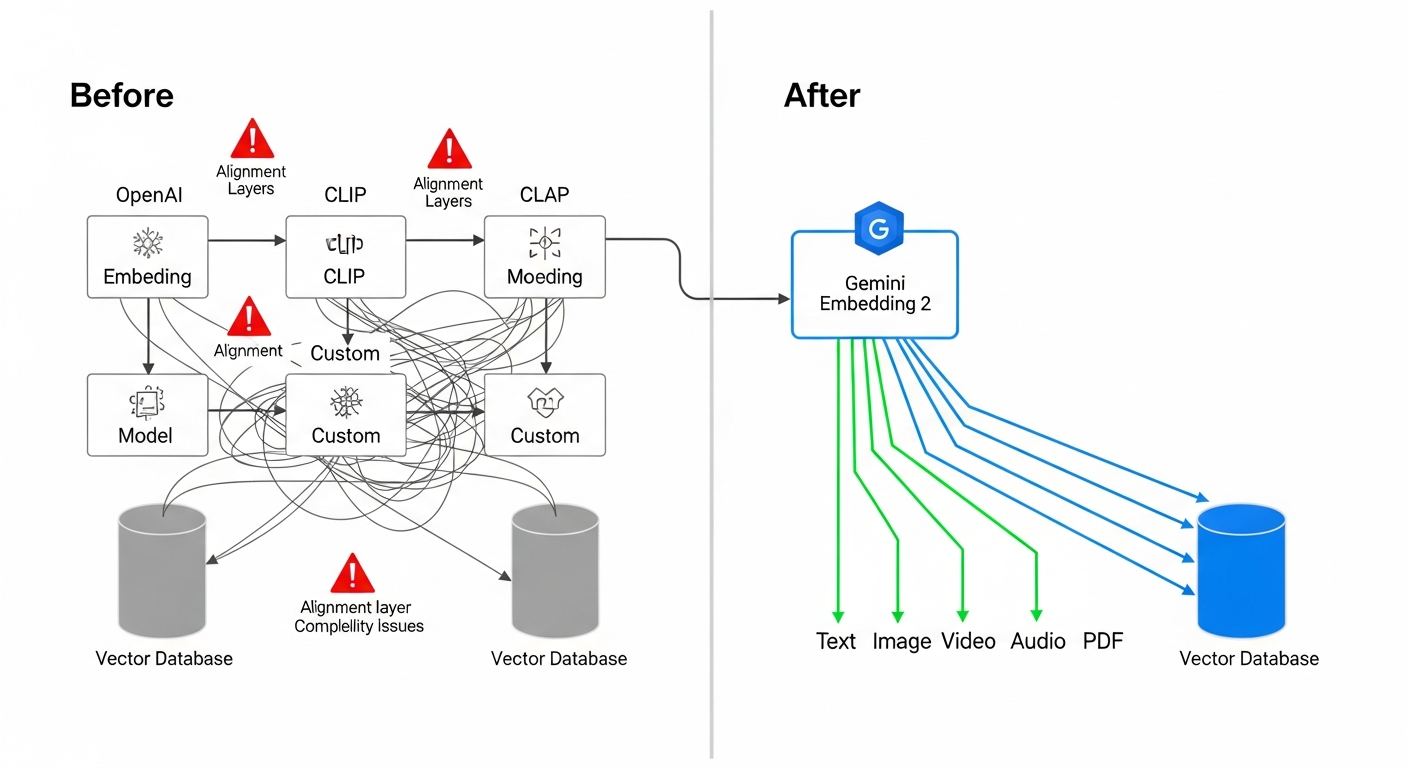
Anyone who’s built a RAG pipeline or semantic search system in the past couple years knows the drill. Text embeddings from OpenAI. Image embeddings from CLIP. Audio gets run through speech-to-text first, then back into text embeddings. Video? You’re mostly on your own.
Separate models. Separate vector spaces. Separate indices. Alignment layers so cross-modal queries sort of work. It gets worse with every modality you add.
Google just collapsed all of that into one model.
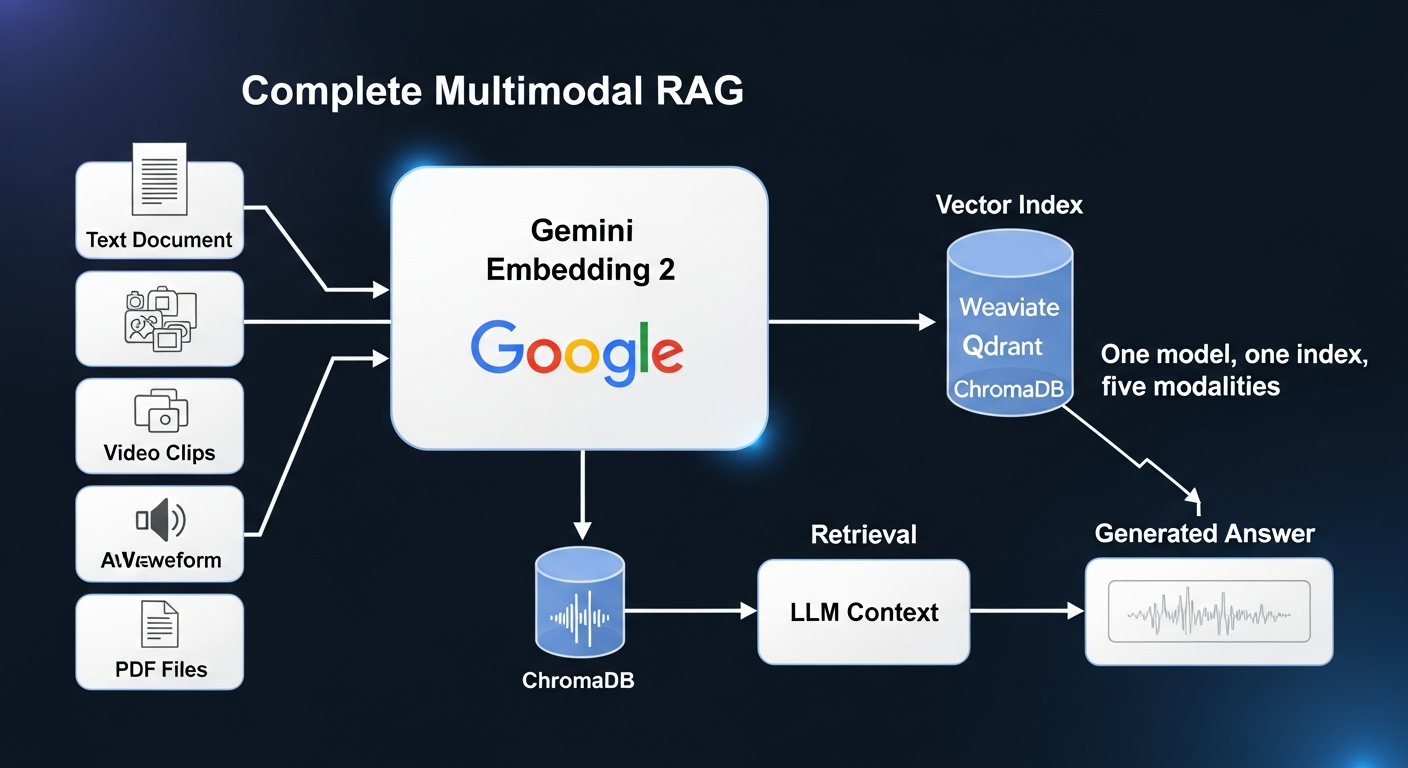
On March 10, 2026, they released Gemini Embedding 2 in public preview. It takes text, images, video, audio, and PDF documents and maps them all into the same embedding space. One model. One vector space. Five modalities.
They also made it free, which I’ll get to.
What it actually does
Gemini Embedding 2 takes any supported input and produces a dense vector. The interesting part is how many input types it handles:
- Text: Up to 8,192 tokens, 100+ languages
- Images: Up to 6 per request (PNG, JPEG)
- Video: Up to 120 seconds (MP4, MOV)
- Audio: Goes straight to vector, no transcription step
- Documents: PDFs up to 6 pages
Everything lands in the same embedding space. Write “sunset over mountains” and the resulting vector is directly comparable to a photo of a sunset, a video clip of one, or someone describing one out loud. Cosine similarity just works across all of them.
There’s another feature worth paying attention to: interleaved multimodal input. You can send an image and its caption together in one request and get back a single embedding that captures both. That’s different from embedding them separately. The combined vector picks up on relationships between the image and the text that you lose when you process them independently.
How it stacks up
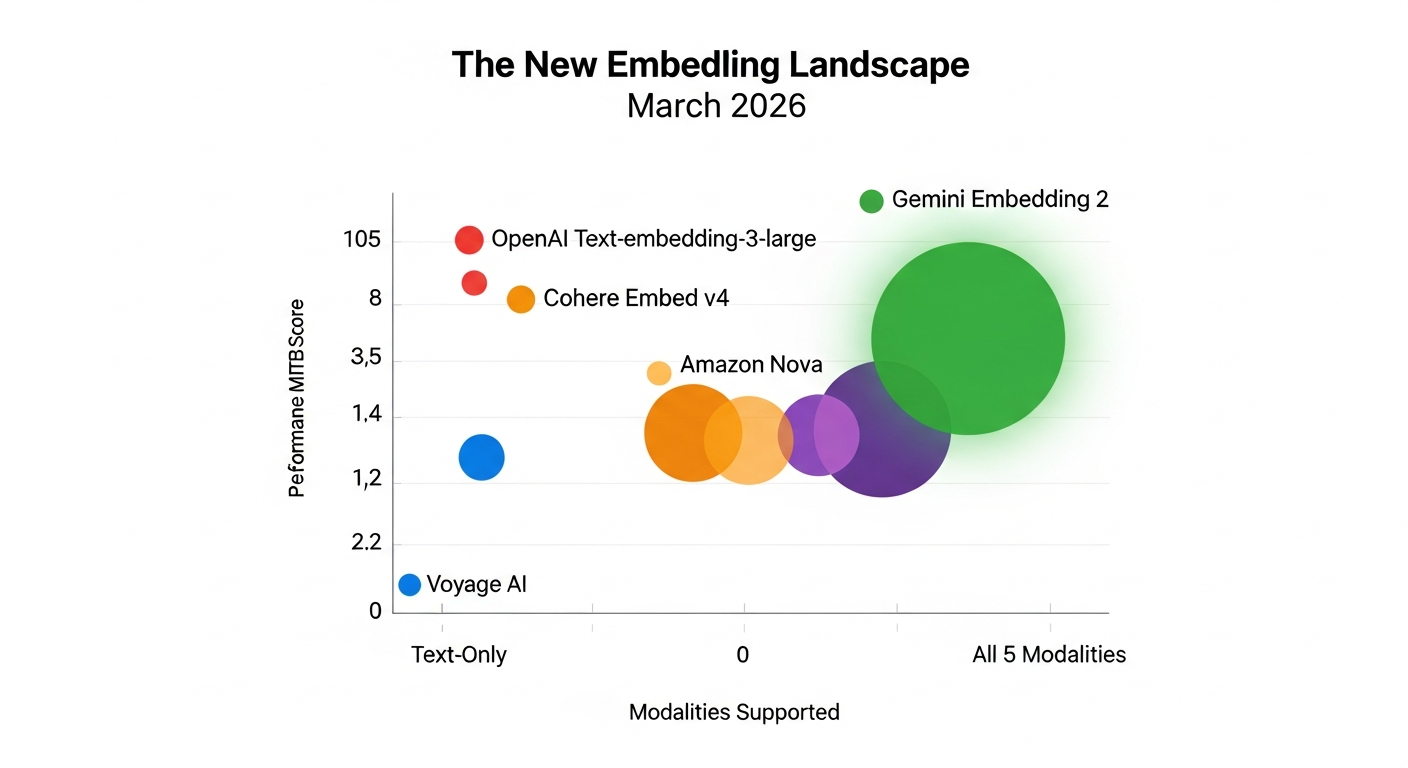
Embedding models have mostly been text-only until now. Here’s the landscape as of March 2026:
| Model | Modalities | Max Dimensions | MTEB Score | Price/1M tokens |
|---|---|---|---|---|
| Gemini Embedding 2 | Text, Image, Video, Audio, PDF | 3,072 | 68.17 | Free |
| OpenAI text-embedding-3-large | Text only | 3,072 | ~64.6 | $0.13 |
| Cohere Embed v4 | Text, Image, PDF | 1,536 | ~67.5 | $0.12 |
| Amazon Nova Multimodal | Text, Image, Video, Audio, PDF | Varies | N/A | Varies |
| Voyage-3-large | Text only | 1,024 | ~67.1 | $0.06-$0.12 |
A few things jump out.
On performance, it beats OpenAI’s best text embedding by about 6% on standard benchmarks. That’s on text-only tasks where OpenAI should have the home court advantage.
On coverage, it’s the only model from a major provider doing all five modalities. Cohere Embed v4 does text, images, and documents but skips video and audio. Amazon Nova handles everything but has less ecosystem support so far.
On price, it’s free on the Gemini API. At a billion tokens per month, you’d pay OpenAI $130. Google charges you nothing.

The business logic here is pretty transparent. Google wants you on Vertex AI, Cloud Storage, and BigQuery. Free embeddings get you in the door. Same playbook as Android.
Flexible dimensions with Matryoshka learning
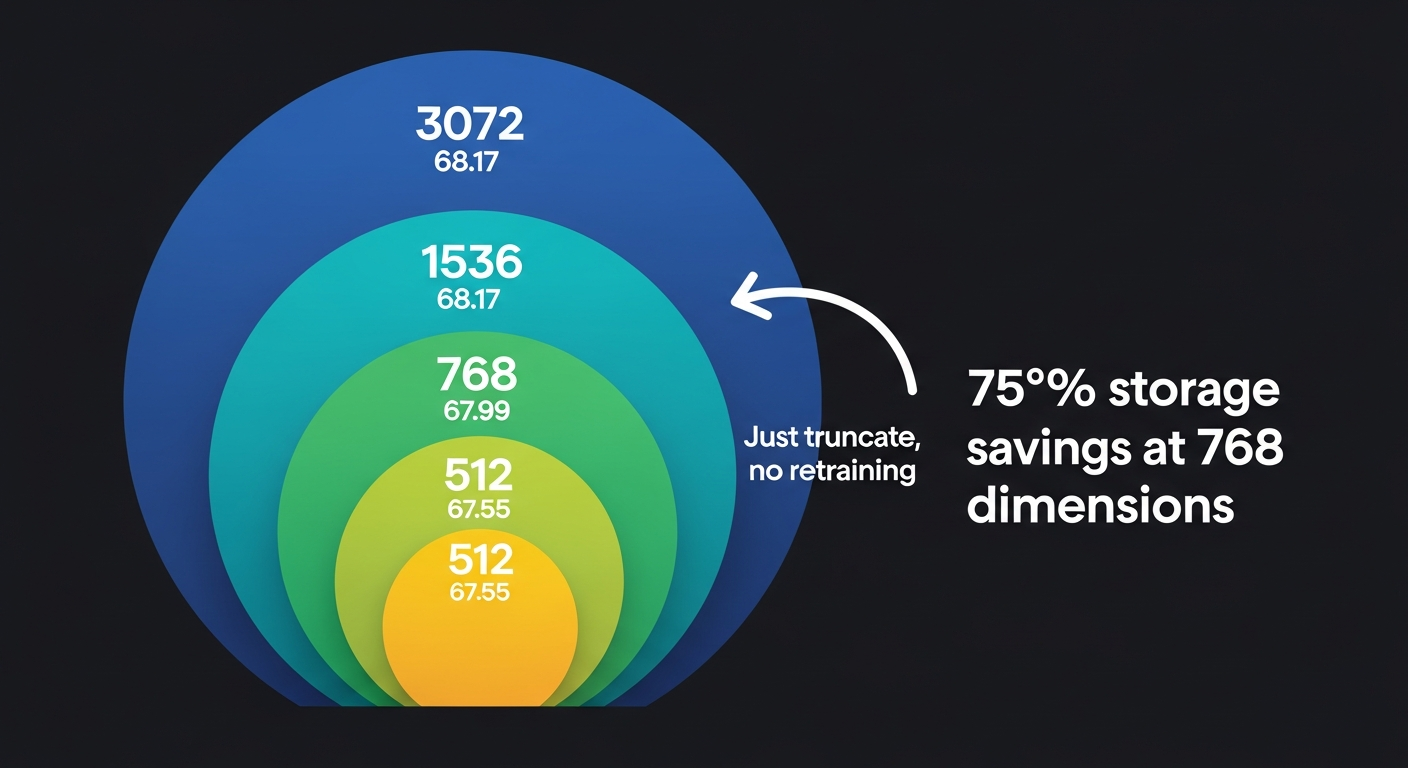
The model uses Matryoshka Representation Learning (MRL), which is showing up in most new embedding models now. The idea is simple: during training, the model puts the most important information in the first dimensions and finer details in later ones.
So you can chop a 3,072-dimension embedding down to 1,536 or 768 by just taking the first N values. No retraining. No second model. Just truncate the vector.
The quality barely moves:
- 3,072 dimensions: 68.17 MTEB
- 1,536 dimensions: 68.17 MTEB
- 768 dimensions: 67.99 MTEB
- 512 dimensions: 67.55 MTEB
Less than 1 point between 1,536 and 512 dimensions. Meanwhile you’re cutting storage by 67%. For most production use cases, 768 is probably the right default. You get high quality at 75% less storage than full resolution.
What early partners are seeing
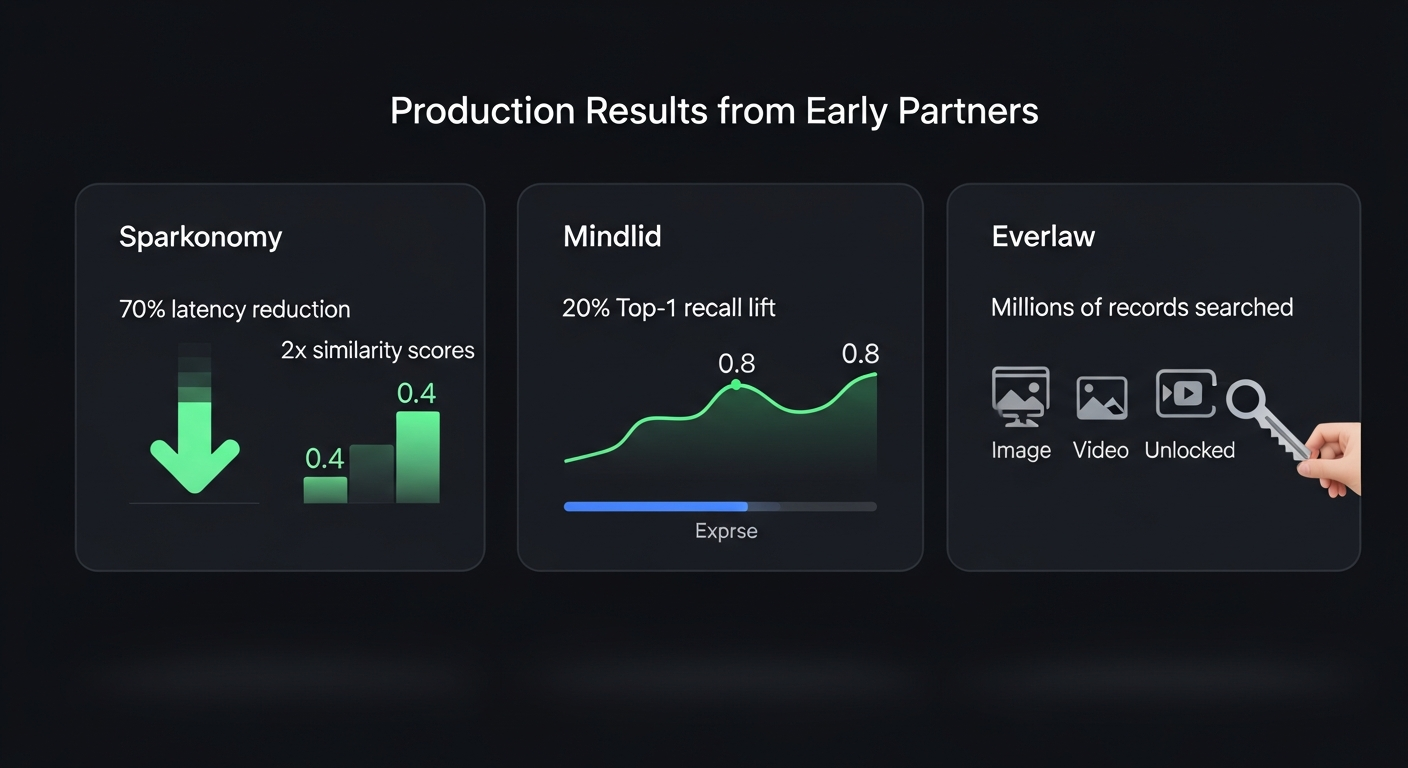
Google shared numbers from three companies already using the model in production.
Everlaw does legal technology. They’re using it for litigation discovery, searching across millions of records. The multimodal part opened up image and video search that they couldn’t do before.
Sparkonomy works in the creator economy. They reported 70% lower latency after dropping LLM inference from their embedding pipeline. The bigger number: similarity scores for text-image and text-video pairs went from 0.4 to 0.8. That’s not a marginal improvement. Their Creator Genome system indexes millions of minutes of video, and this doubled the quality of cross-modal matching.
Mindlid builds a personal wellness app. They saw a 20% lift in top-1 recall when they started combining text memories with audio and visual embeddings. They also noted the API was easy to swap in: “drops right into existing workflows with minimal changes.”
The multimodal RAG shift
This release lands at an interesting moment. RAG systems are moving beyond text retrieval toward something people are calling “Context Engines.”
The number that keeps coming up: 90% of enterprise data isn’t text. It’s images, PDFs, audio recordings, video calls, design files. Text-only RAG was always working with a fraction of what’s actually available.
A unified multimodal embedding space changes the math. Instead of maintaining separate indices for each content type with alignment layers between them, you get one index that handles everything:
- Search your video library with a text query
- Pull images, audio, and documents into LLM context alongside text
- Classify content across media types with one model
- Find duplicate content even when it exists in different formats
- Search audio and video without transcribing first
Combine this with hybrid retrieval (sparse + dense), better chunking strategies, and adaptive token pruning, and you can build multimodal RAG systems that would have required a dedicated team six months ago.
The trade-offs
There are real downsides to think about.
The vector space is incompatible with the older gemini-embedding-001. If you’re already on Google embeddings, you’ll need to re-embed your whole corpus. That’s not free, even if the API calls are.
The 8,192 token budget is shared across modalities. Pack a long text document and several images into one request and you could run out of room.
It’s still in preview. The model ID is gemini-embedding-2-preview. Stability and performance guarantees aren’t where they’d be for a GA release.
And the free pricing, while great for your budget, creates lock-in. Once you’ve built your index on these embeddings, switching costs go up with every vector you store.
Getting started
The API is clean. Here’s text, an image, and audio embedded in one call:
from google import genai
from google.genai import types
client = genai.Client()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
"What is the meaning of life?",
types.Part.from_bytes(data=image_bytes, mime_type="image/png"),
types.Part.from_bytes(data=audio_bytes, mime_type="audio/mpeg"),
],
)
print(result.embeddings)
Available through the Gemini API and Vertex AI. Integrations exist for LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB, and Vector Search.
What I’d take away from this
If you’re building multimodal retrieval, this is the obvious starting point right now. Nothing else matches the combination of modality coverage, benchmark performance, and cost.
Text-only embedding models still work fine for pure text workloads. But for anything with mixed content types, the gap is getting hard to justify.
Plan for the re-embedding cost if you’re migrating. It’s a one-time hit but it’s real.
Start with 768 dimensions for most things. Go to 1,536 or 3,072 when the marginal quality actually matters for your use case.
The bigger picture is that embeddings are becoming a commodity. When the best multimodal model is free, the value moves upstream to what you build on top of it. Spend your engineering time on retrieval quality, chunking strategies, and application logic. The embedding model itself is no longer the bottleneck.